피크 형상 중심의 머신러닝을 통한 고해상도 MALDI-TOF 질량 스펙트럼으로부터 피크 추출법 개발 및 합성고분자 분석에의 응용 [MALDI Application]
엠에스팁 No.352
MALDI-TOFMS(Matrix-Assisted Laser Desorption/ionization Time-of-Flight Mass Spectrometer)는 폴리머 분석에서 강력한 도구입니다. 고해상도 MALDI-TOFMS는 반복 단위와 말단기의 원소 조성으로 고분자 계열을 쉽게 식별할 수 있으며, 이온 강도 분포로부터 고분자의 분자량 분포를 계산할 수 있습니다. 실제 산업재료 분석에서는 분자량 분포와 말단기가 다른 고분자 혼합물을 분석하는데, 복잡한 질량 스펙트럼을 한눈에 볼 수 있는 KMD(Kendrick Mass Defect) 분석이 사용되고 있다. KMD 분석은 고분자 계열이 KMD 플롯이라는 다이어그램에서 직선으로 시각화되기 때문에 복잡한 질량 스펙트럼에 포함된 고분자 계열의 수와 상대량을 시각화할 수 있습니다. 또 다른 기능은 추적 구성 요소의 검색을 용이하게 한다는 것입니다. KMD 플롯은 질량 스펙트럼에서 피크를 추출하여 생성되므로 분석할 피크와 노이즈 피크를 적절하게 구분하는 것이 중요합니다. MALDI-TOFMS의 질량 스펙트럼은 종종 이온 강도가 증가함에 따라 기하급수적으로 감소하는 노이즈 피크를 나타냅니다. m / z. 이 피크는 넓고 형태가 왜곡되어 재현성이 떨어집니다. 고분해능 MALDI-TOFMS JMS-S3000 “SpiralTOF™” 시리즈를 사용하여 측정한 질량 스펙트럼에서 분석하려는 피크는 피크 폭이 좁아 비정보적 피크와 육안으로 구분할 수 있습니다. 그러나 전체 질량 스펙트럼에 걸쳐 식별을 수행하고 작은 피크를 포함하는 것은 시간이 많이 걸리고 비효율적입니다. 일반적인 자동 피크 결정에서는 피크 면적 값이 이온 강도로 사용됩니다. 따라서 넓은 노이즈 피크가 분석하고자 하는 피크와 높이가 같은 경우 이온 세기가 높아져 임계값으로 일률적으로 구분하기 어려울 수 있다. 그림 1은 프로필 질량 스펙트럼과 분석할 피크 및 일반적인 피크 결정 후 노이즈 피크를 보여줍니다. 피크 목록에서 분석할 피크는 빨간색으로, 노이즈 피크는 녹색으로 표시됩니다. 프로필 스펙트럼에서 1u마다 약한 노이즈 피크가 관찰되었습니다. 프로파일 스펙트럼에서는 피크 폭을 기준으로 분석할 피크를 식별할 수 있으나, 피크 검출 후에는 노이즈 피크의 이온 강도(피크 면적)가 상대적으로 커져 분석할 피크를 식별하기 어렵습니다. . 이 문제를 해결하기 위해 본 보고서에서는 피크 모양에 초점을 맞춘 감독 데이터로 기계 학습을 사용하여 질량 스펙트럼의 피크가 분석 대상 피크인지 노이즈 피크인지 식별하는 방법의 개발을 설명합니다.
실험
기계 학습을 위한 데이터를 생성하기 위해 평균 분자량이 400, 600, 1000, 2000인 폴리에틸렌 글리콜(PEG)을 10mg/mL로 준비한 다음 1:1:2:4(v/v/v/ v) 비율(PEG 혼합물). 또한, 100배 희석된 PEG 혼합물을 저농도 PEG 혼합물로 준비하였다. 매트릭스는 DCTB(10 mg/mL)를 사용하였고, 양이온화제로는 소듐 트리플루오로아세테이트(1 mg/mL)를 사용하였다. SpiralTOF 양이온 모드에서 JMS-S3000 "SpiralTOF™-plus"를 사용하여 질량 스펙트럼을 획득했습니다. 기계 학습 노이즈 제거는 msPeakFinder에서 구현됩니다. KMD 분석은 msRepeatFinder로 수행되었습니다.
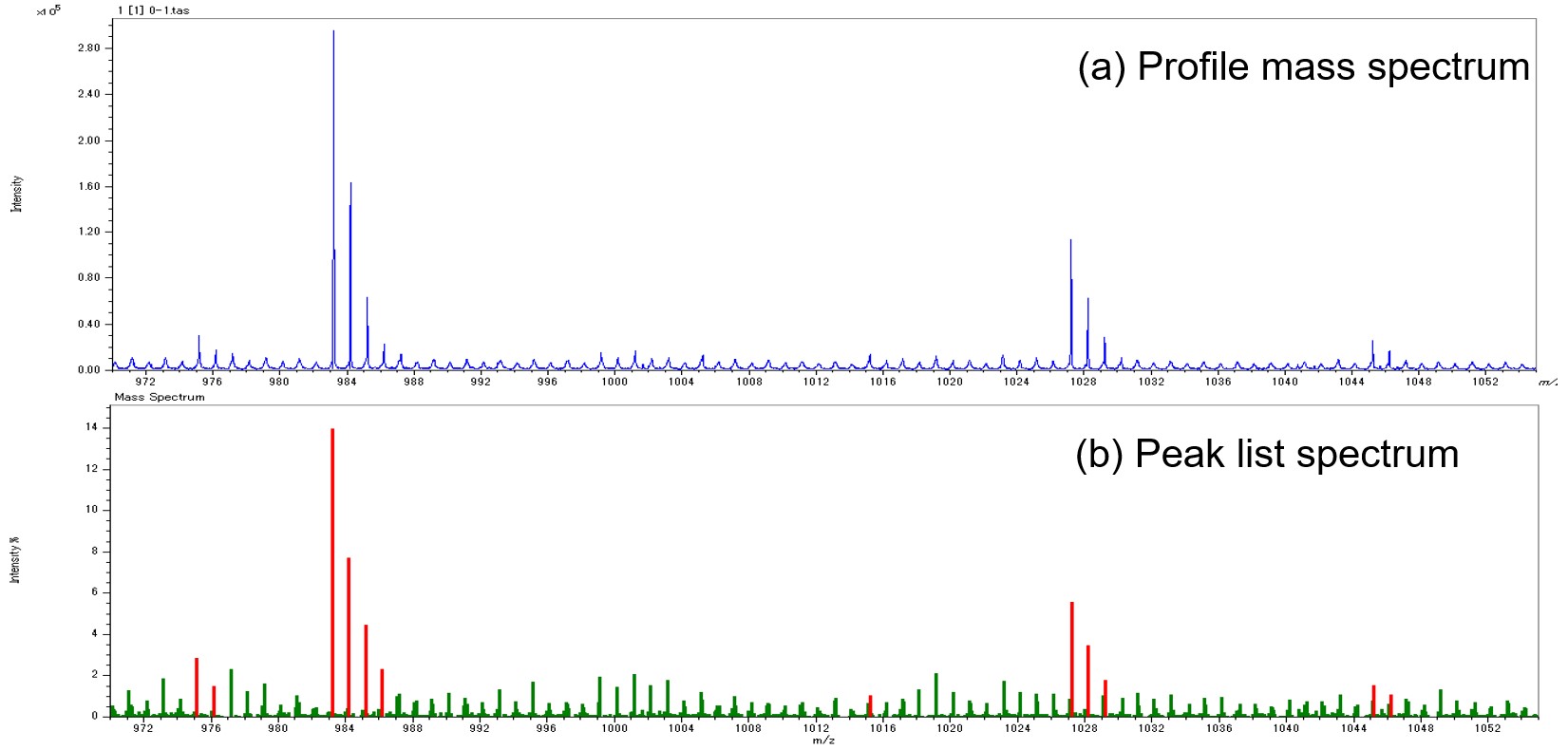
그림 1 고분해능 MALDI-TOFMS(a)의 프로필 질량 스펙트럼과 기존의 피크 검출 방법을 사용한 피크 목록 스펙트럼.
기계 학습 방법
기계 학습을 위해 cGAN(Conditional Generative Adversarial Network)을 채택했습니다. cGAN은 입력된 조건 데이터에 따라 생성된 데이터를 출력하므로 조건 데이터에서 생성된 데이터로의 변환이라고 볼 수 있습니다. 이 방법은 관측된 질량 스펙트럼을 입력하고 노이즈 피크가 제거된 의사 질량 스펙트럼을 출력하는 개념을 기반으로 노이즈 피크 제거에 적용했습니다. 그림 2는 이 방법에 대한 기계 학습 모델을 만드는 절차의 흐름도를 보여줍니다. 순서도에서 노란색 배경은 사람의 개입이고 녹색은 자동입니다. 먼저 훈련 데이터를 위해 PEG 혼합물의 질량 스펙트럼을 획득했습니다(그림 3a). 획득한 질량 스펙트럼을 기존 방법으로 피크 검출하고 피크 목록을 만든 후 분석할 피크를 전문가가 피크 모양을 기준으로 결정하고 추출했습니다(그림 3b 빨간색 화살표). 분석하고자 하는 피크는 관찰된 이온 세기와 상관없이 일정한 높이로 설정하였고 피크 모양은 Gaussian 분포로 생성하여 pseudo-mass 스펙트럼을 생성하였다(그림 3c). 이 방법은 획득한 질량 스펙트럼과 의사 질량 스펙트럼을 짝지어 학습 데이터의 원본 데이터로 사용하는 방법입니다. 이제는 훈련 데이터의 수를 늘리기 위해 많은 수의 질량 스펙트럼을 획득하는 데 시간과 노력이 필요합니다. 따라서 원본 데이터를 1,600점마다 나누고 분할 시작점을 1,024번 변경하여 하나의 원본 데이터에서 총 4쌍의 훈련 데이터를 생성했습니다. 이렇게 생성된 훈련 데이터를 이용하여 머신러닝 모델을 생성하였다. 수치. XNUMX는 개념도를 보여준다. 수집된 질량 스펙트럼은 Generator에 의해 의사 질량 스펙트럼으로 변환됩니다. 이 측정된 질량 스펙트럼과 생성기를 통해 변환된 의사 질량 스펙트럼의 조합과 트레이닝 데이터의 측정된 질량 스펙트럼과 의사 질량 스펙트럼의 조합을 판별기로 판별하여 생성기의 품질을 향상시켰다.
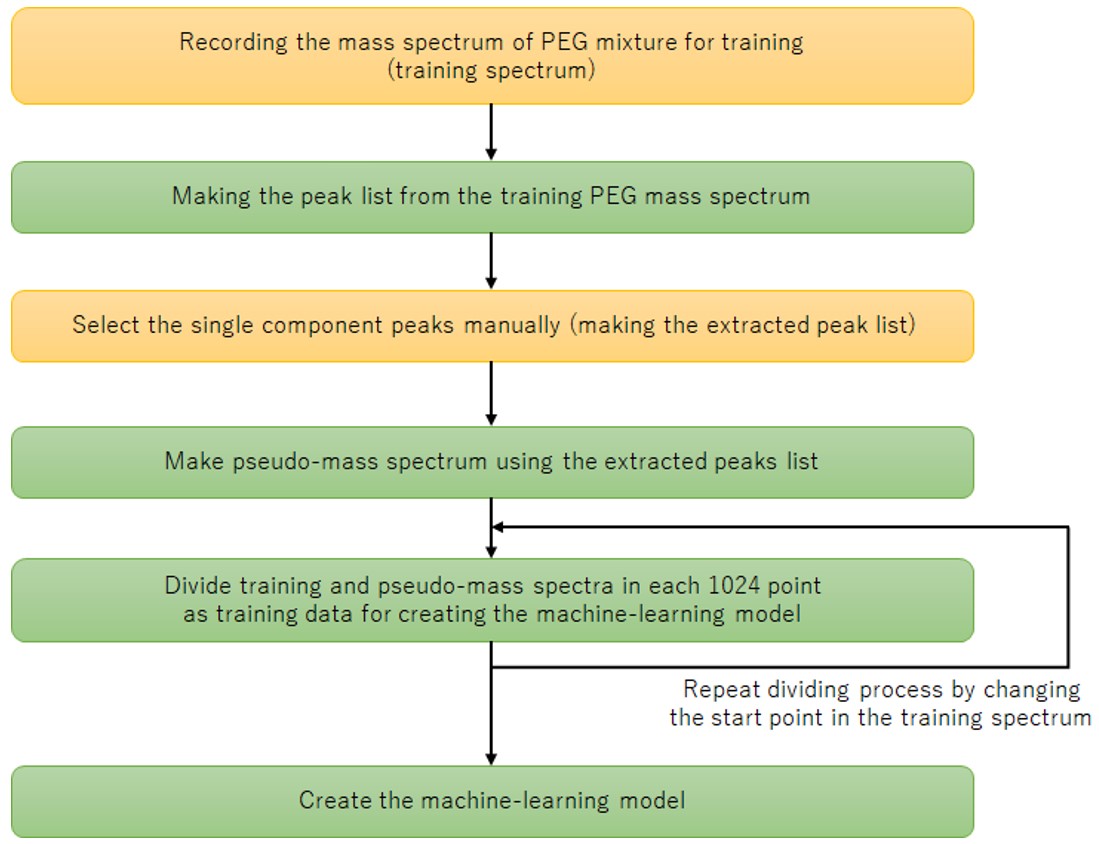
그림 2 기계 학습 모델을 만드는 순서도.
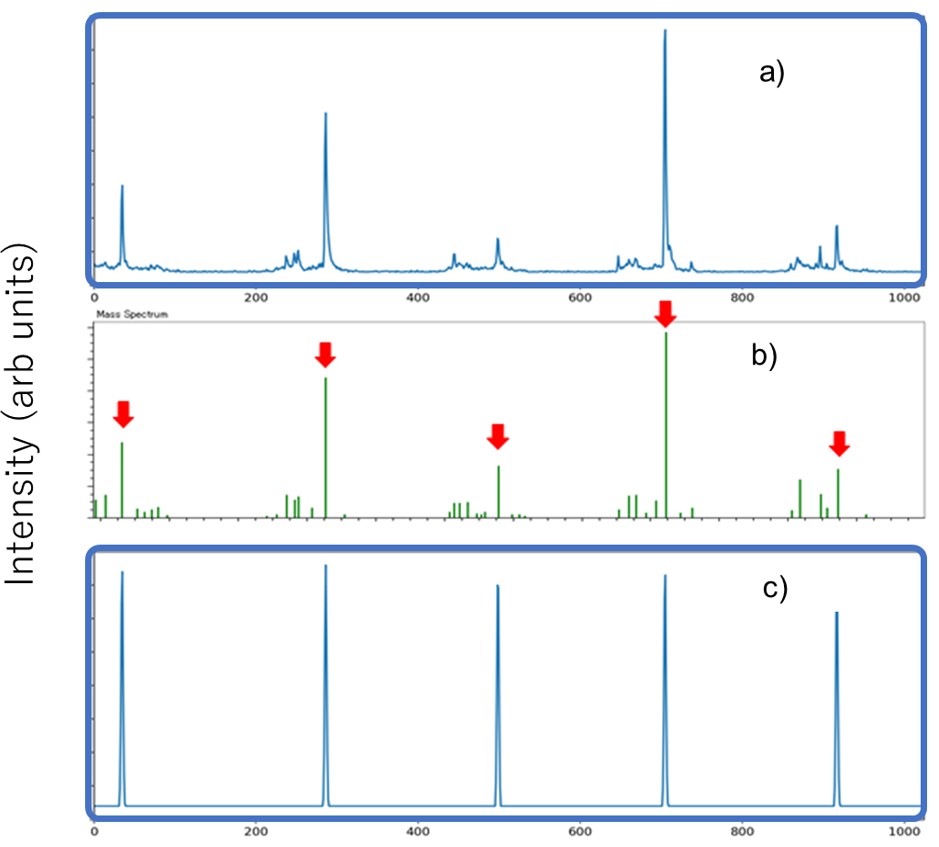
그림 3 프로필 질량 스펙트럼(a), 피크 목록(b) 및 의사 질량 스펙트럼(c) 간의 관계.
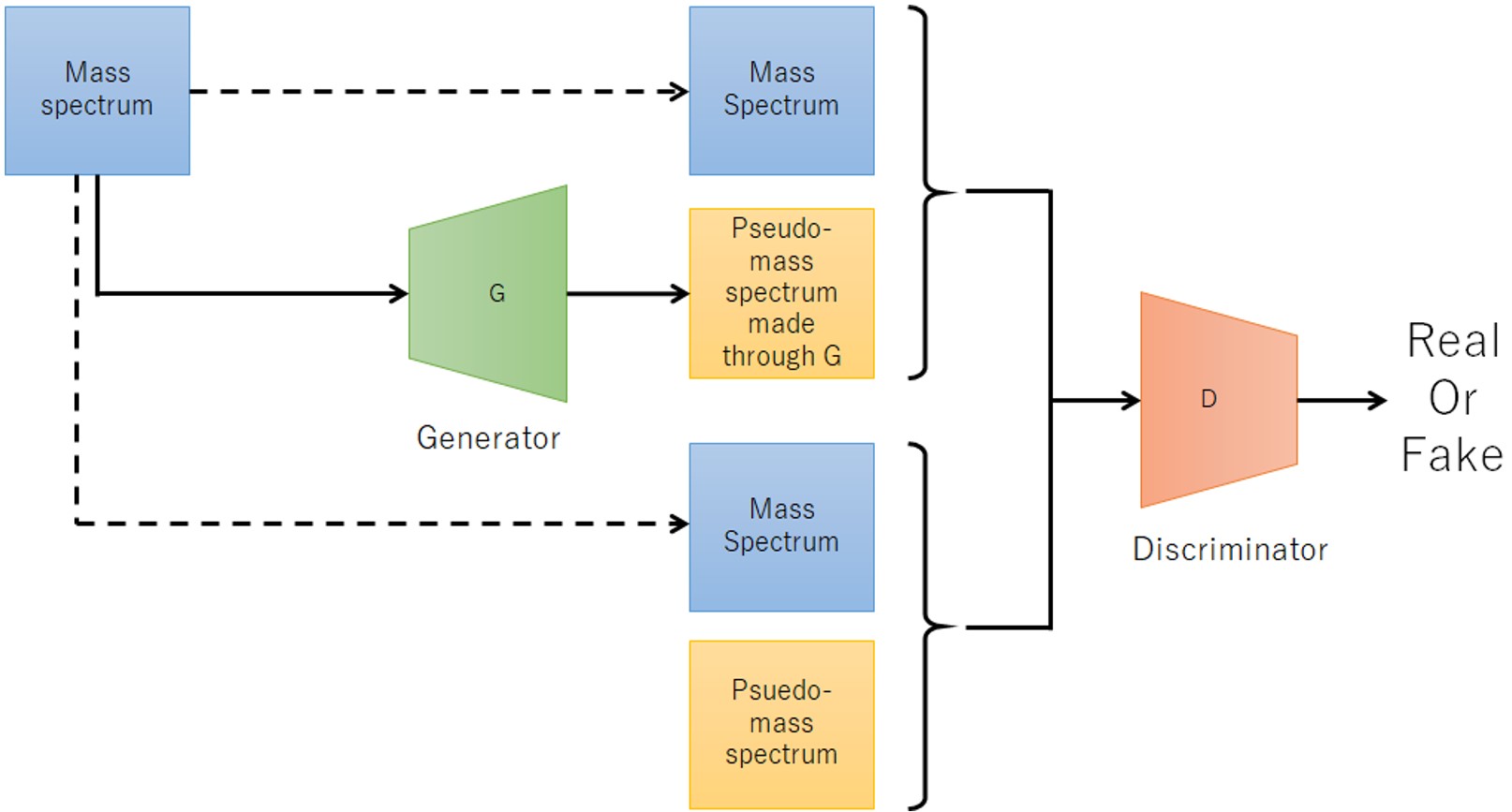
그림 4 cGAN을 이용한 머신러닝 모델 제작 방식.
머신러닝 모델 검증 및 적용
다음으로 생성된 기계 학습 모델을 사용하여 실제 노이즈 제거 절차를 보여줍니다(그림 5). 순서도에서 노란색 배경은 사람의 개입이고 녹색은 자동입니다. 획득한 질량스펙트럼을 기존 방식으로 피크검출하고 이와 병행하여 1,024개 포인트로 나누어 기존 방식으로 결정된 피크의 머신러닝 모델을 이용하여 의사질량스펙트럼으로 변환하여 일치하는 피크만 의사 질량 스펙트럼의 피크 위치가 남아 있고 노이즈가 제거된 피크 목록이 생성됩니다. 즉, m / z 이 방법으로 추출한 피크 리스트의 이온 강도 및 이온 강도는 기존 방법의 값입니다. 여기에서 훈련 데이터를 생성하는 데 사용된 PEG 혼합 질량 스펙트럼에서 노이즈 피크를 제거하려고 했습니다. 그 결과를 표 1에 정리하였다. 기존의 방법으로 PEG 혼합물의 질량 스펙트럼에서 총 4,390개의 피크가 검출되었다. 그 중 왼쪽 상단의 1,265개 피크와 오른쪽 하단의 3,105개 피크(전체의 99.5%)가 학습 데이터 생성 시 수동으로 내린 판단과 기계 학습 모델의 판단 결과가 일치합니다. 오른쪽 상단의 14개 피크는 머신러닝 모델 생성 시 분석할 피크로 결정되었으나 머신러닝 모델에서는 노이즈 피크로 결정되었습니다. 이러한 피크 모양은 약간 왜곡되어 전문가도 판단하기 어려운 것으로 확인되었다. 좌측 하단의 6개 피크는 트레이닝 데이터 생성 시 노이즈 피크로 결정되었으나 기계 학습 모델에서 분석할 피크로 결정되었습니다. 이는 학습 데이터를 준비할 때 사람의 실수로 발생한 것으로 확인되었습니다. 이후 이 실수를 수정한 훈련 데이터로 머신러닝을 다시 수행했다. 기계 학습 모델을 생성하는 데 사용된 질량 스펙트럼을 사용하여 모델을 검증하는 것이 효과적이라고 생각합니다. 마지막으로 저농도 PEG의 질량 스펙트럼을 이용하여 피크 추출을 수행하였고, KMD plot으로 전개된 결과를 Figure 6에 나타내었다. Figure 6a는 측정된 질량 스펙트럼, Figure XNUMXb는 KMD plot이다. KMD 플롯의 빨간색 점은 기계 학습으로 분석할 피크로, 녹색 점은 노이즈 피크로 결정했습니다. 이 결과로부터 PEG 시리즈는 특히, m / z <1,500.
요약
이상과 같이 저역대에서 자주 관찰되는 노이즈 피크를 제거하여 KMD 분석을 보다 효율적으로 수행할 수 있음을 확인할 수 있었다.m / z 기계 학습 모델을 사용하여 고해상도 MALDI-TOFMS 데이터의 영역.
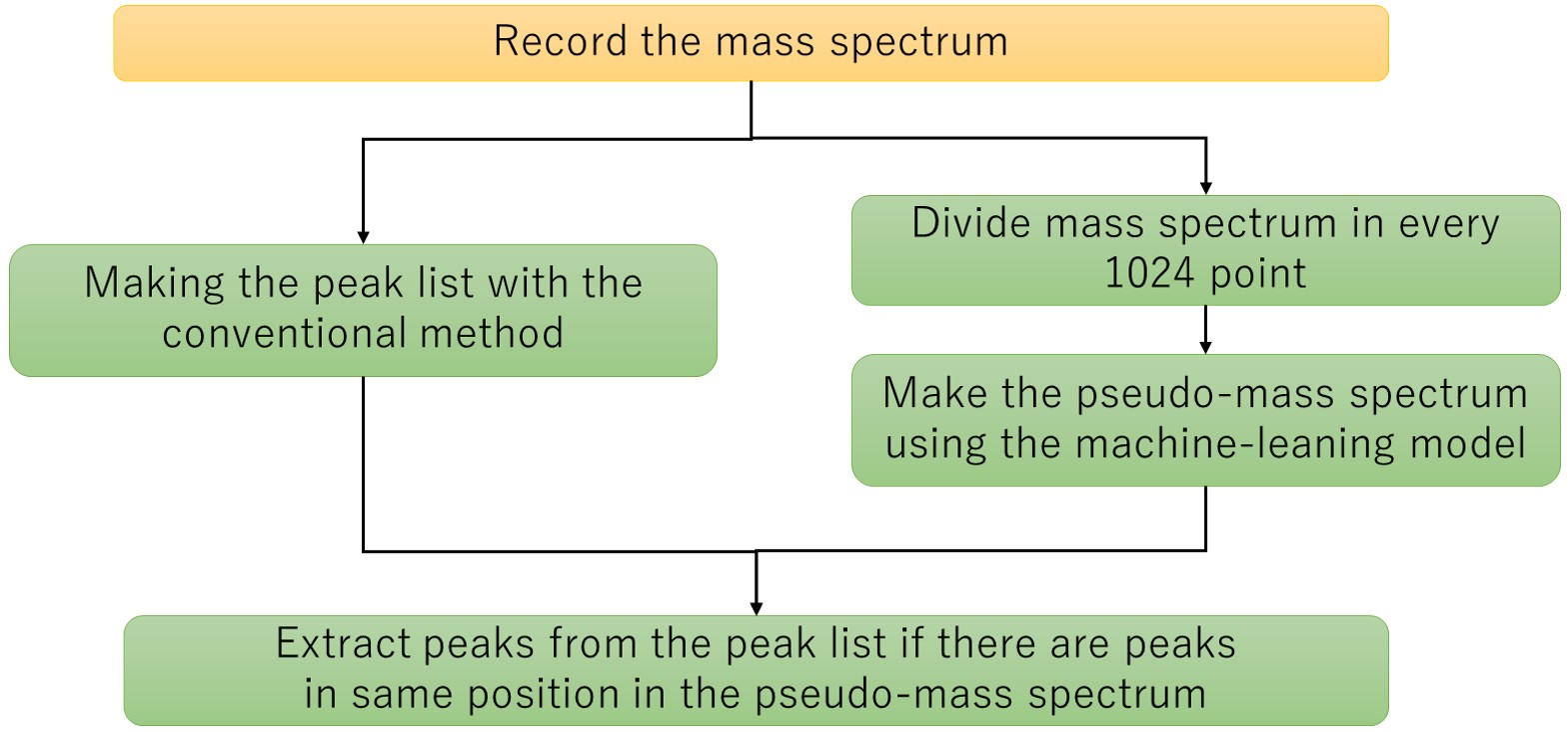
그림 5 기계 학습 모델에 의한 추출 피크 목록 작성 흐름도.

표 1 훈련 데이터로 사용된 PEG 혼합물의 피크 목록과 기계 학습 모델로 추출한 것의 비교.
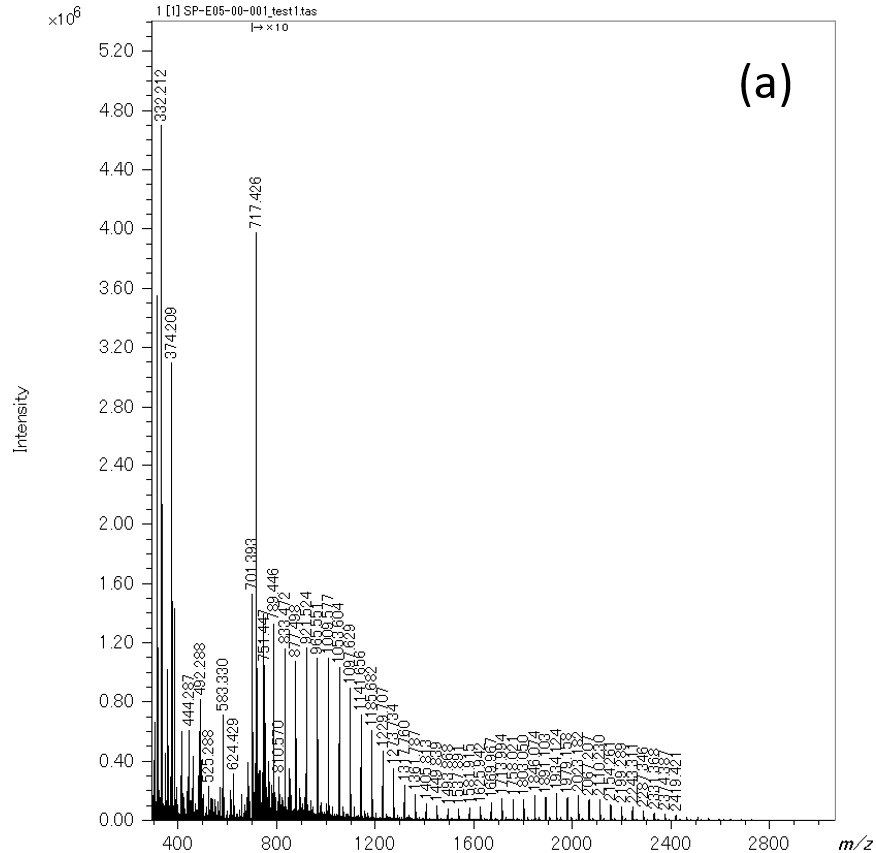
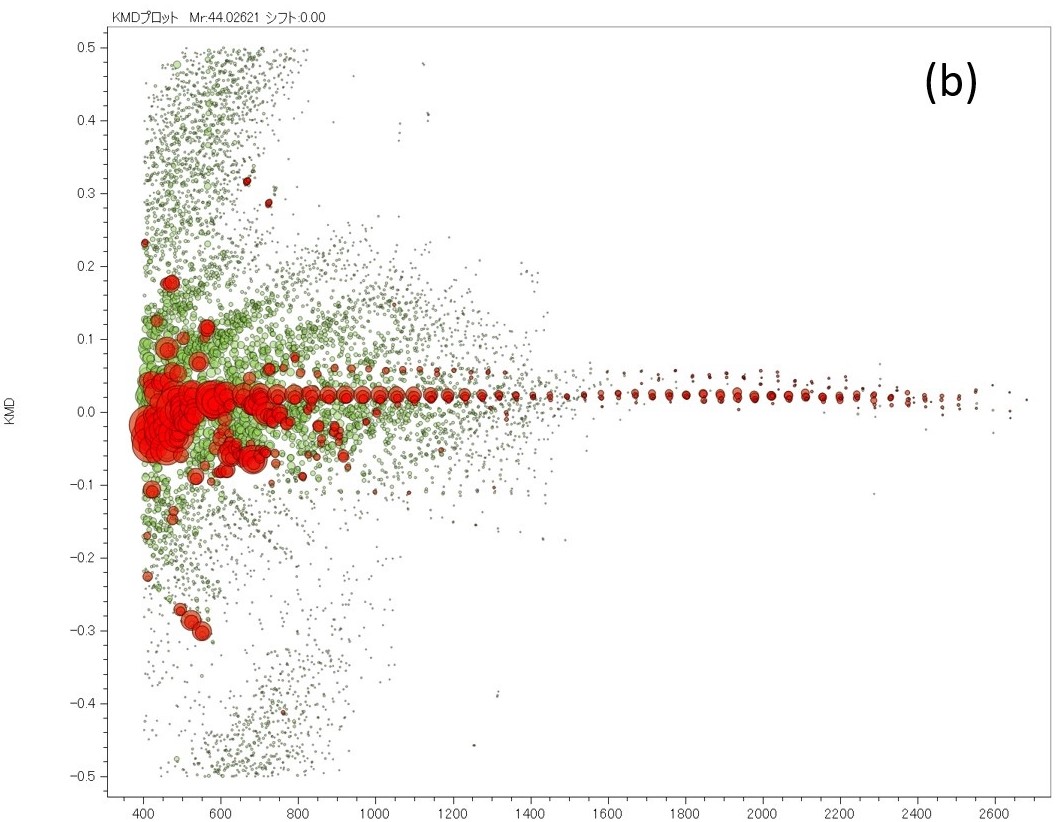
그림 6 저농도 PEG 혼합물(a)의 질량 스펙트럼과 기계 학습 모델로 분리된 추출된 피크 목록(빨간색) 및 노이즈 필 목록(녹색)의 KMD 플롯.